goods.txt
13059 2019-12-23 06:12:29 15281 2019-12-23 06:12:29 14905 2019-12-23 06:12:29 14622 2019-12-23 06:12:29 19817 2019-12-23 06:12:29 13009 2019-12-23 06:12:29 14572 2019-12-23 06:12:29 11081 2019-12-23 06:12:29 17228 2019-12-23 06:12:29 16931 2019-12-23 06:12:29 18945 2019-12-23 06:12:29 18013 2019-12-23 06:12:29 11879 2019-12-23 06:12:29 17429 2019-12-23 06:12:29 17570 2019-12-23 06:12:29 12141 2019-12-23 06:12:29 11758 2019-12-23 06:12:29 15326 2019-12-23 06:12:29 14718 2019-12-23 06:12:29 13607 2019-12-23 06:12:29 16815 2019-12-23 06:12:29 11954 2019-12-23 06:12:29 12841 2019-12-23 06:12:29 18054 2019-12-23 06:12:29 12340 2019-12-23 06:12:29 17825 2019-12-23 06:12:29 10948 2019-12-23 06:12:29 17236 2019-12-23 06:12:29 14181 2019-12-23 06:12:29 16364 2019-12-23 06:12:29 10167 2019-12-23 06:12:29 15274 2019-12-23 06:12:29 15835 2019-12-23 06:12:29 15301 2019-12-23 06:12:29 10411 2019-12-23 06:12:29 15269 2019-12-23 06:12:29 19951 2019-12-23 06:12:29 13363 2019-12-23 06:12:29 16532 2019-12-23 06:12:29 17222 2019-12-23 06:12:29 14913 2019-12-23 06:12:29 18991 2019-12-23 06:12:29 15675 2019-12-23 06:12:29 16375 2019-12-23 06:12:29 12181 2019-12-23 06:12:29 12846 2019-12-23 06:12:29 19642 2019-12-23 06:12:29 17573 2019-12-23 06:12:29 16103 2019-12-23 06:12:29 18154 2019-12-23 06:12:29 11089 2019-12-23 06:12:29 14158 2019-12-23 06:12:29 18991 2019-12-23 06:12:29 14799 2019-12-23 06:12:29 12870 2019-12-23 06:12:29 12153 2019-12-23 06:12:29 16096 2019-12-23 06:12:29 16640 2019-12-23 06:12:29 18872 2019-12-23 06:12:29 10108 2019-12-23 06:12:29 15066 2019-12-23 06:12:29 11491 2019-12-23 06:12:29 18612 2019-12-23 06:12:29 18973 2019-12-23 06:12:29 15727 2019-12-23 06:12:29 13312 2019-12-23 06:12:29 19056 2019-12-23 06:12:29 14585 2019-12-23 06:12:29 10003 2019-12-23 06:12:29 15521 2019-12-23 06:12:29 12853 2019-12-23 06:12:29 15755 2019-12-23 06:12:29 11276 2019-12-23 06:12:29 14950 2019-12-23 06:12:29 18219 2019-12-23 06:12:29
wc.scala
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
object wc {
def main(args: Array[String]): Unit = {
//指定为root用户
System.setProperty("HADOOP_USER_NAME", "root")
//获取conf文件
val conf = new SparkConf()
//项目名
.setAppName("wc")
//允许本地运行
.setMaster("local")
//获取上下文
val sc = new SparkContext(conf)
//hdfs上获取源文件
//14816 2019-12-23 06:12:30
//14816 2019-12-23 06:12:30
//11077 2019-12-23 06:12:30
val lines = sc.textFile("hdfs://10.0.0.20:8020/goods.txt")
//以\t进行拆分,获取第一个索引
//14816
//14816
//11077
val words = lines.map(_.split("\t")(0))
//每个索引末尾加1
//(14816,1)
//(14816,1)
//(11077,1)
val tulp = words.map((_,1))
//key相同的进行累加
//(14816,2)
//(11077,1)
val re = tulp.reduceByKey(_+_)
//将k和v调换位置,再将k降序排序"false"再调换k和v
val jx = re.map(x => (x._2,x._1)).sortByKey(false ).map(x => (x._2,x._1))
//转为字符串以\t进行分割
//14816 2
//11077 1
val str = jx.map( x=> {x._1 + "\t" + x._2})
//结果输出到hdfs上
str.saveAsTextFile("hdfs://10.0.0.20:8020/sp/wc2")
}
}
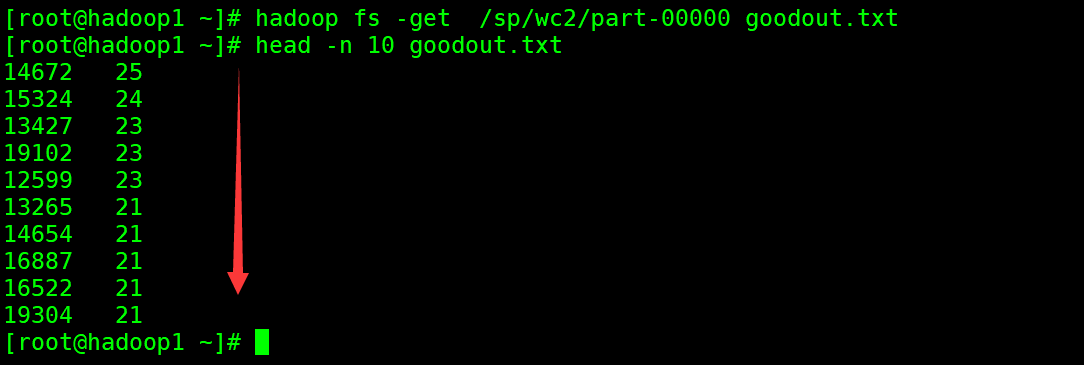
结果